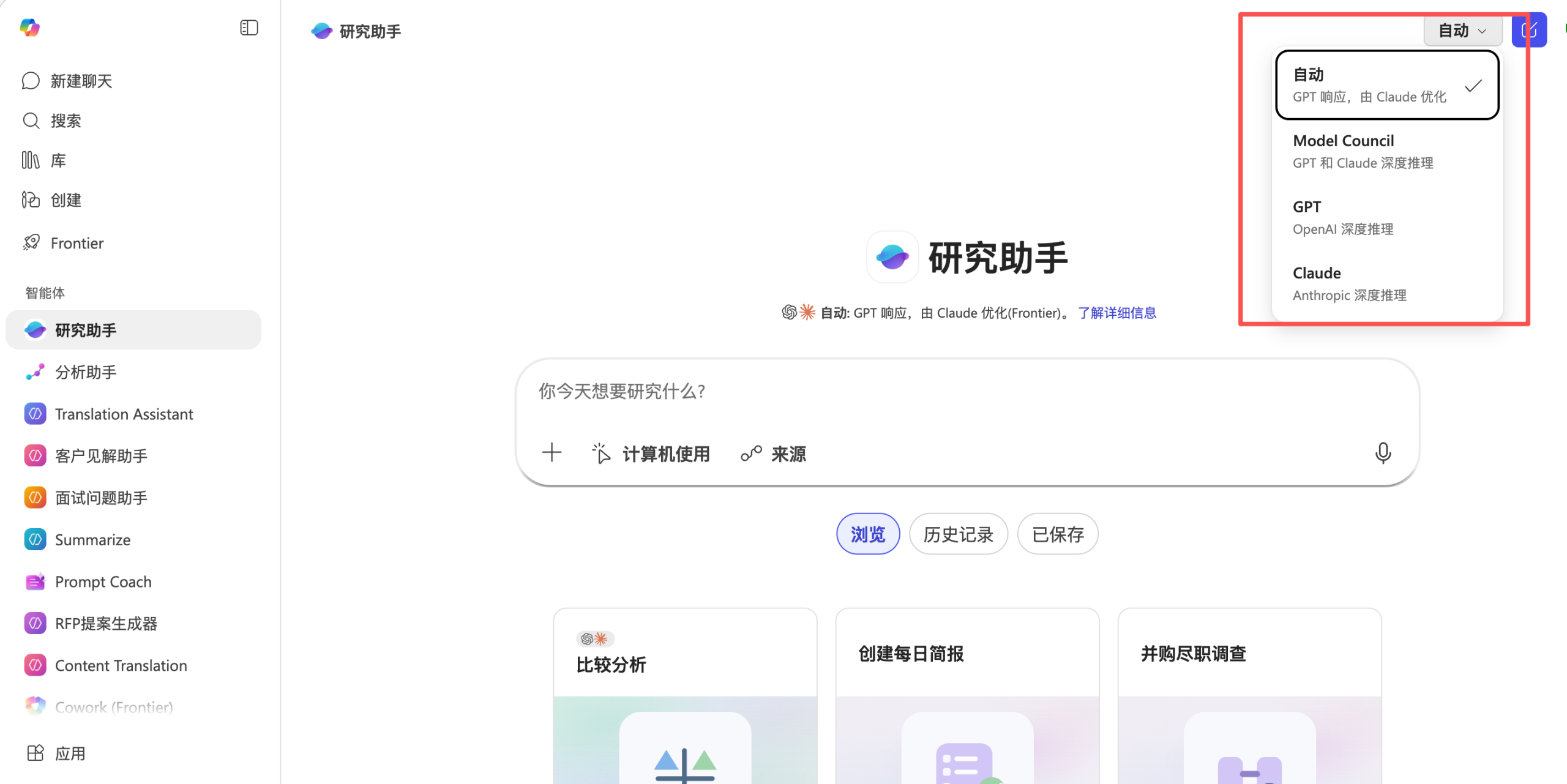
2026 年 3 月 30 日,微软为 Microsoft 365 Copilot 的研究员 (Researcher) 智能代理正式引入了多模型智能 (Multi-Model Intelligence) 能力。这项升级让 Researcher 不再依赖单一大模型,而是能够编排多种基础模型协同工作——将研究任务拆解为规划、检索、综合与引用等步骤,并自动为每个步骤择优路由最合适的模型。更关键的是,微软同步推出了 Critique(自审) 和 Council(理事会) 两大机制,让不同模型之间形成”生成—审校”和”并行比较—仲裁综合”的协作关系,从根本上提升 AI 研究输出的准确性、深度和可信度。在 DRACO(Deep Research Accuracy, Completeness, and Objectivity)基准测试中,涵盖 10 个领域的 100 项复杂研究任务,启用 Critique 的 Researcher 综合得分提升 +7.0 分(SEM ±1.90),较此前表现最佳的 Perplexity Deep Research(Claude Opus 4.6 模型)高出 13.88%。

知识型工作的痛点:为什么我们需要”AI 研究团队”
知识型员工在信息搜寻上的时间消耗惊人。 据 McKinsey 的分析,员工平均每天花费 1.8 小时、每周 9.3 小时用于搜索和整理信息。IDC 的数据更为激进:知识工作者每天约花 2.5 小时(约占工作日的 30%) 在信息检索上。这意味着大量宝贵的分析与创造时间被消耗在了资料收集环节。
与此同时,单一 AI 模型在处理深度调研任务时面临可靠性瓶颈。正如 Pareekh Consulting 首席执行官 Pareekh Jain 指出的,多模型系统”就像配了一个聪明的专业助手加一个严格的审稿人”,但”仍然是渐进式改进而非魔法——它减少错误但不能消除错误”。而 Counterpoint Research 研究副总裁 Neil Shah 则强调,”多模型系统只有与企业内部数据(如 CRM 和 HRM 系统)整合后才能发挥全部潜力”,确保 AI 洞见能够反映企业的独特市场定位和决策者的具体需求。
Microsoft 365 Copilot Researcher 正是为弥补这一缺口而设计的智能代理。与标准 Copilot 聊天体验不同,Researcher 专注于需要深度推理、跨多源解决问题的复杂分析场景,它有意花费更多处理时间来检索和分析,以交付包含视觉图表、结构化分区和引用来源的完整报告。Researcher 从 Web 和用户有权访问的工作内容(文件、电子邮件、会议和聊天记录)中获取见解,且遵循组织已有的权限、策略和合规性规则。
Critique:串联式双模型自审——让 AI 先审自己的稿
Critique 的核心设计是将”生成”与”评估”拆解为两个独立环节,由不同模型各司其职。 据微软官方文档描述,当 Anthropic 模型已启用且用户在模型选择器中选择 “Auto” 模式时,Researcher 的报告将先由 GPT 生成,随后自动交由 Claude 执行第二轮推理审查——加固结构完整性、优先引用权威来源、确保关键陈述都有清晰的引文支撑。
这种架构的深层逻辑在于:让一个模型的输出接受另一个模型的批判性检验,形成内建的纠错回路。据智通财经报道,第一个模型负责初步的任务规划、信息检索与草案撰写,而第二个模型则充当”资深评审角色”,专门核实事实真实性、审校逻辑链条并精炼最终报告。这种多模型交互的自我修正机制,旨在从根本上克服 AI 模型中普遍存在的”幻觉”现象。
基准测试数据提供了量化证据:
| 评估维度 | 提升幅度 | 统计显著性 |
|---|---|---|
| 分析广度与深度 (Breadth and Depth of Analysis) | +3.33 | p < 0.0001 |
| 表达质量 (Presentation Quality) | +3.04 | p < 0.0001 |
| 事实准确性 (Factual Accuracy) | +2.58 | p < 0.0001 |
| 综合得分 | +7.0 分 (SEM ±1.90) | — |
基于 DRACO 基准(Zhong et al., arXiv:2602.11685, 2026 年 2 月),覆盖 10 个领域的 100 项复杂研究任务。Researcher with Critique 的综合得分较论文中表现最佳的 Perplexity Deep Research(Claude Opus 4.6 模型)高出 13.88%。
Critique 的开放性值得关注:它并不绑定单一供应商模型。据智通财经报道,该系统通过集成 OpenAI 的 GPT 系列、Anthropic 的 Claude 系列以及微软自研的 Phi 系列模型,实现了跨厂商的协同——例如以 GPT 的创意生成能力产出初稿,再由 Claude 进行严格的逻辑审计。
需要注意的权衡: 虽然基准测试结果令人振奋,但 Pareekh Jain 提醒企业应保持审慎,”这相当于一个最佳情景测试;它表明 AI 模型可以互相检查并发现错误,但真实企业数据要混乱得多——存在矛盾信息和过时文档”。此外,”如果两个 AI 模型思路相似,审查者可能会遗漏同样的错误”。
Council:并行多模型议会——汇聚多元 AI 视角
Council 代表了更进一步的多模型协作范式:并行独立求解 + 仲裁综合。 根据微软官方说明,Model Council 将同一问题同时交给 GPT 和 Claude 等多个深度推理研究代理处理,每个模型各自独立生成一份完整的研究报告,然后系统添加一份轻量级的综合”封面信”,指出各模型的共识点、分歧点和独特贡献。
据微软在消息中心的说明,Council 生成的内容包含三个层次:
- 两份独立的完整研究报告,分别来自不同推理模型(如 GPT 和 Claude)
- 一份简明综合摘要,总结共识、分歧与各自独特贡献
- 评判模型还会指出规模、框架或解释上的差异
这种设计的实践价值在于:不同模型因训练数据和架构差异,对同一问题的侧重点往往不同。当两个模型的结论高度一致时,用户可以更有信心地采用该结论;当两者存在分歧时,分歧本身就是有价值的信号——它提示用户该问题存在多种合理解读,需要进一步人工判断。aibase.com 的分析文章指出,这种多智能体协作的效果显著优于任何单一模型,能有效过滤错误信息,降低 AI 幻觉问题。
Council 的操作方式也十分直观:用户在 Microsoft 365 Copilot 应用中打开 Researcher 代理,从模型下拉菜单中选择 “Model Council”,然后输入提示即可。如果用户只想使用单一模型,也可以单独选择 GPT 或 Claude。
应用场景:多模型智能如何改变企业调研方式
场景一:文献综述与市场调研的加速引擎
Researcher 能自动从 Web 和企业工作内容中提取信息,撰写结构化、带有引文的响应。在市场调研场景中,它可以自动执行网页检索获取最新行业数据,同时从企业内部的 SharePoint 和 OneDrive 文档中检索既有分析,调用表格抽取模型从统计报告中提取关键数字,最终生成包含图表和引用来源的完整报告。
据 Microsoft Tech Community 的信息,通过模型路由与工具调用,多模型 Researcher 带来了更快的竞品分析、RFP 草拟与可溯源报告生成等业务成效。启用 Critique 后,报告中的关键数据和结论都经过第二模型的事实核查,减少了分析师人工校对的负担。
场景举例:一位咨询顾问需要在两天内完成某行业的竞争格局分析报告。以往需要手动搜索数十个信息源、逐一阅读并摘录要点、核对数据来源。现在可以在 Microsoft 365 Copilot 中打开 Researcher,选择 Auto(Critique)模式,提出研究问题。Researcher 会自动规划检索路径、汇总内外部信息源、由 GPT 生成初稿并由 Claude 审校事实与引用,最终交付一份结构清晰、来源可溯的报告初稿——顾问只需在此基础上进行专业判断和定制修改。
场景二:跨模型对比增强决策信心
Council 模式的独特价值在于为同一个问题提供多元视角。当企业面临重大决策(如技术选型、并购尽职调查、政策合规评估)时,不同模型可能关注不同的风险因素和机会点。例如,一个模型可能更关注财务风险数据,另一个可能更擅长法规分析。通过 Council 的综合摘要,决策者可以快速识别哪些结论是多方共识、哪些存在不确定性,从而在充分知情的前提下做出判断。
场景三:企业合规约束下的安全 AI 调研
对于金融、医疗与法务等行业,数据安全与合规是 AI 落地的前提。Researcher 的设计深度嵌入了 Microsoft 365 的企业安全体系:通过 Purview 数据防泄漏和 Microsoft Graph 权限绑定,AI 只能访问用户有权查看的内部数据,且遵循组织的合规策略。现有的安全、合规和数据处理政策在启用 Critique/Council 后继续适用,不会发生变化。这为上述行业的规模化 AI 辅助研究提供了合规落地的基础。
对 IT 管理者的实操指南:部署与治理
Critique 和 Council 目前作为预览功能,仅面向加入 Microsoft 365 Copilot Frontier 计划的组织开放,使用者需持有 Microsoft 365 Copilot(Premium)许可证。在部署前,IT 管理员需要完成以下准备:
- 审查 AI 模型访问设置:确认租户是否已在 Microsoft 365 管理中心启用 Anthropic Claude 模型访问
- 评估治理与合规需求:Critique 和 Council 没有独立的开关——两者在 Anthropic 和 Claude 报告生成功能开启时同步启用
- 通知帮助台与支持团队,并更新内部培训材料
- 如不计划启用预览功能,无需采取任何操作
治理层面的挑战不容忽视。 多模型系统引入了新的运维复杂性:与以往单一输入-输出的流程不同,组织现在需要追踪一条包含初始草稿、Critique 审校和最终输出的交互链。Pareekh Jain 指出,”这会产生更大的审计日志,安全与合规团队必须审查这些日志来理解决策是如何做出的”;同时”也增加了成本和延迟,因为一个问题可能触发多次模型调用”。此外,问责变得更复杂——”如果出了问题,更难确定是哪个环节失败了:是生成器、审核者,还是管理它们的编排系统”。
Neil Shah 建议,企业必须将模型到输出选择流程的治理放在首位,并持续监控和校准多模型系统的输出质量,使其成为流程质量管理 (Process Quality Management) 的基本组成部分。企业还需要建立结构化的输出评估机制,确保跨决策过程的可追溯性,并持续改进多模型系统的管理方式。
趋势研判:从模型参数竞赛到多智能体协同生态
Copilot Researcher 引入多模型智能,标志着 AI 应用架构的一个重要转向:竞争焦点正在从孤立模型的参数规模转向多智能体系统的集成与协同能力。据智通财经分析,随着 Critique 和 Council 的落地,微软在企业级生产力工具市场的竞争壁垒将进一步加固。aibase.com 的分析文章也指出,AI 助手正从通用型工具向专业化、行业化的”数字员工”演进——GPT 擅长创意与生成,Claude 侧重安全与严谨,两者互补为企业级高可靠应用树立了新标杆。
对开发者和架构师而言,Researcher 的多模型编排模式提供了可参考的系统设计范式:通过模型路由、任务拆解和跨模型校验,可以在自有 AI 应用中复现类似的”生成—审核—综合”流程,提升系统的输出可靠性。这种设计理念将推动 AI 系统从”单兵作战”走向”团队作战”。
需要正视的权衡是:多模型架构在带来更高质量输出的同时,也意味着更高的推理成本、更长的响应延迟和更复杂的运维负担。企业在决定是否启用这些功能时,需要在输出质量提升与资源和管理成本增加之间进行权衡。对于高价值、低频次的深度调研任务(如战略规划、法规合规评估),多模型协同的收益大概率超过额外成本;而对于高频、轻量的日常查询,标准 Copilot 聊天可能仍是更高效的选择。
多模型智能加持下的 Microsoft 365 Copilot Researcher,为企业知识工作提供了一种全新的可能——让多个 AI 模型像一支专业调研团队那样协同工作,互相校验,各展所长。从Critique 的”写完自审”到 Council 的”多方会诊”,再到与 Purview 和 Graph 深度整合带来的合规保障,这套机制不仅提升了 AI 输出的可信度,也为不同角色的从业者(调研员、开发者、IT 管理员、合规负责人)提供了差异化的实践价值。当然,多模型协作并非万能——它增加了系统复杂性和运维成本,基准测试中的表现也未必能完全复现于企业真实数据环境。但正如行业观察所言,未来的 AI 竞争将不再是孤立模型的参数比拼,而是看谁能构建出更高效、更稳定的多智能体协同生态。对于技术社区和企业从业者来说,现在正是理解、评估并准备拥抱这一工作方式变革的时机。